环境准备
完成GBase8c主备式部署(含CM、VIP配置)
完成Python通过psycopg2库连接数据库的连通性测试
远程客户端系统版本:openEuler-22.03-LTS-SP4-x86_64
测试脚本(下载地址见下文)
远程连接工具:MobaXterm
测试流程
登录远程openEuler系统,下载测试脚本并修改脚本参数;
确认数据库集群运行状态正常;
在MobaXterm中新建标签页,重新登录openEuler系统;
一个标签页执行写入测试脚本
ha_write_test.py,另一个标签页执行读取测试脚本ha_read_test.py;执行
cm_ctl switchover命令完成第一次主备倒换,观察两个Python脚本的输出结果;再次执行
cm_ctl switchover命令完成第二次主备倒换,观察脚本输出;重启主节点操作系统,触发第三次主备倒换,观察脚本输出;
待原主节点重启完成且集群状态恢复至
normal后,重启当前备节点操作系统(此时该节点为备节点,无抢占主库行为),触发第四次主备倒换,观察脚本输出。
测试步骤
登录远程openEuler并配置测试脚本
脚本下载与解压
脚本下载地址:https://github.com/kiraster/gbase8c-HA-test-scripts
脚本存放路径:/opt/ha-test
下载命令:
# 创建并切换至目标目录
mkdir -p /opt/ha-test
cd /opt/ha-test
# 下载脚本压缩包并命名为ha-test.zip
wget -O ha-test.zip https://codeload.github.com/kiraster/gbase8c-HA-test-scripts/zip/refs/heads/main
解压命令:
# 将压缩包内容解压至当前目录(忽略层级,仅提取文件)
unzip -j ha-test.zip
解压后查看文件列表(示例):
[root@gbase8c ha-test]# ll
total 48
-rw-r--r--. 1 root root 14345 Jan 22 00:50 ha_read_test.py
-rw-r--r--. 1 root root 10515 Jan 22 21:36 ha-test.zip
-rw-r--r--. 1 root root 15437 Jan 22 00:50 ha_write_test.py
-rw-r--r--. 1 root root 743 Jan 22 00:50 README.md
脚本参数修改
批量替换两个脚本中的IP地址:将脚本中
172.x.x.231的x.x部分替换为31.100,最终网段统一为172.31.100.x;配置数据库连接信息:可新增
.env文件按以下格式填写,或直接在代码中硬编码配置:
GB_HOST=172.31.100.230
GB_PORT=15400
GB_USER=testuser
GB_PWD=yourtestuserpasswd
GB_DB=postgres
运行脚本并观察输出
启动测试脚本
运行写入测试脚本:
python3 ha_write_test.py
运行读取测试脚本:
python3 ha_read_test.py
多窗口观察准备
注:需同时监控两个脚本的输出,建议参考以下截图布局拆分窗口,便于同步观察写入与读取日志:
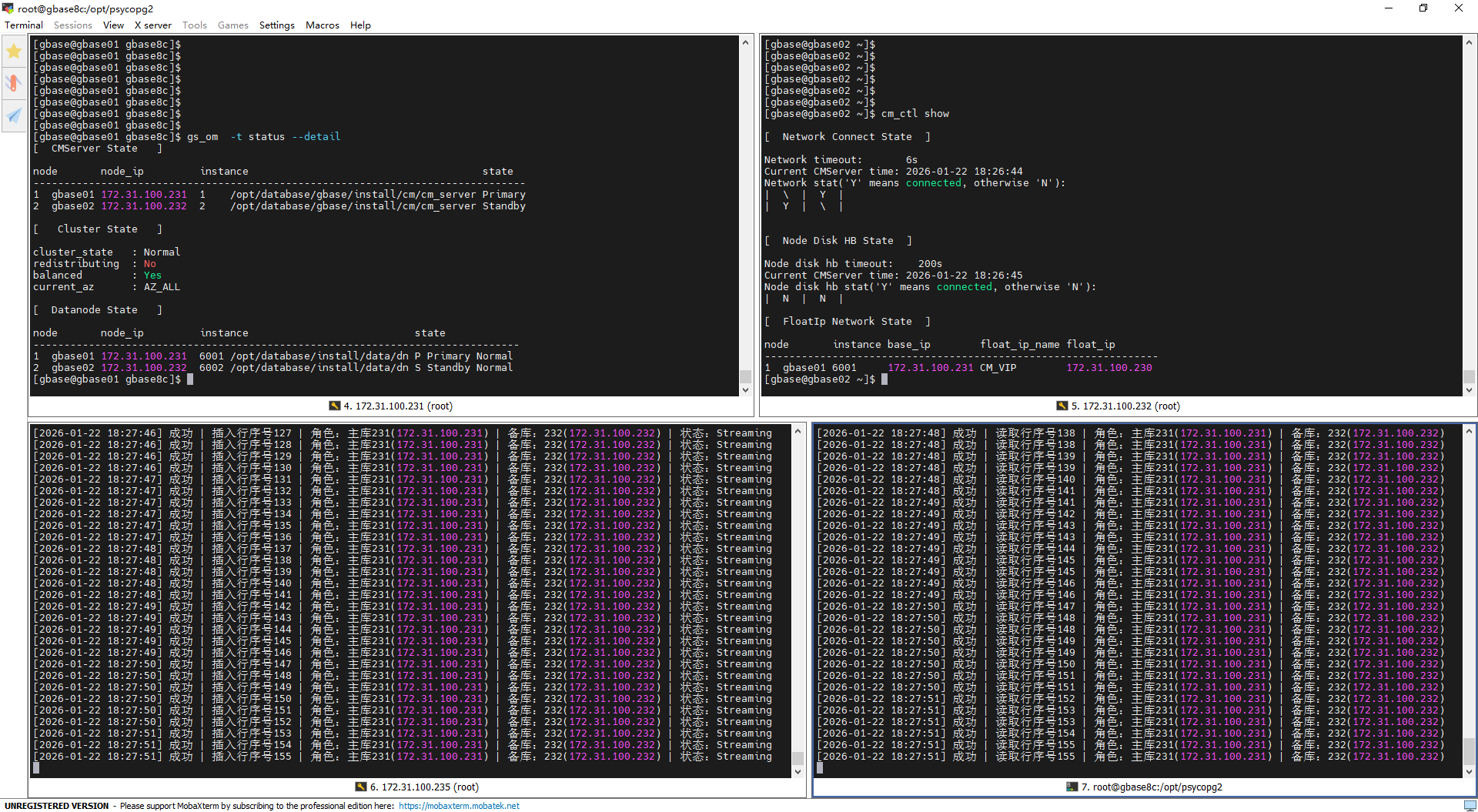
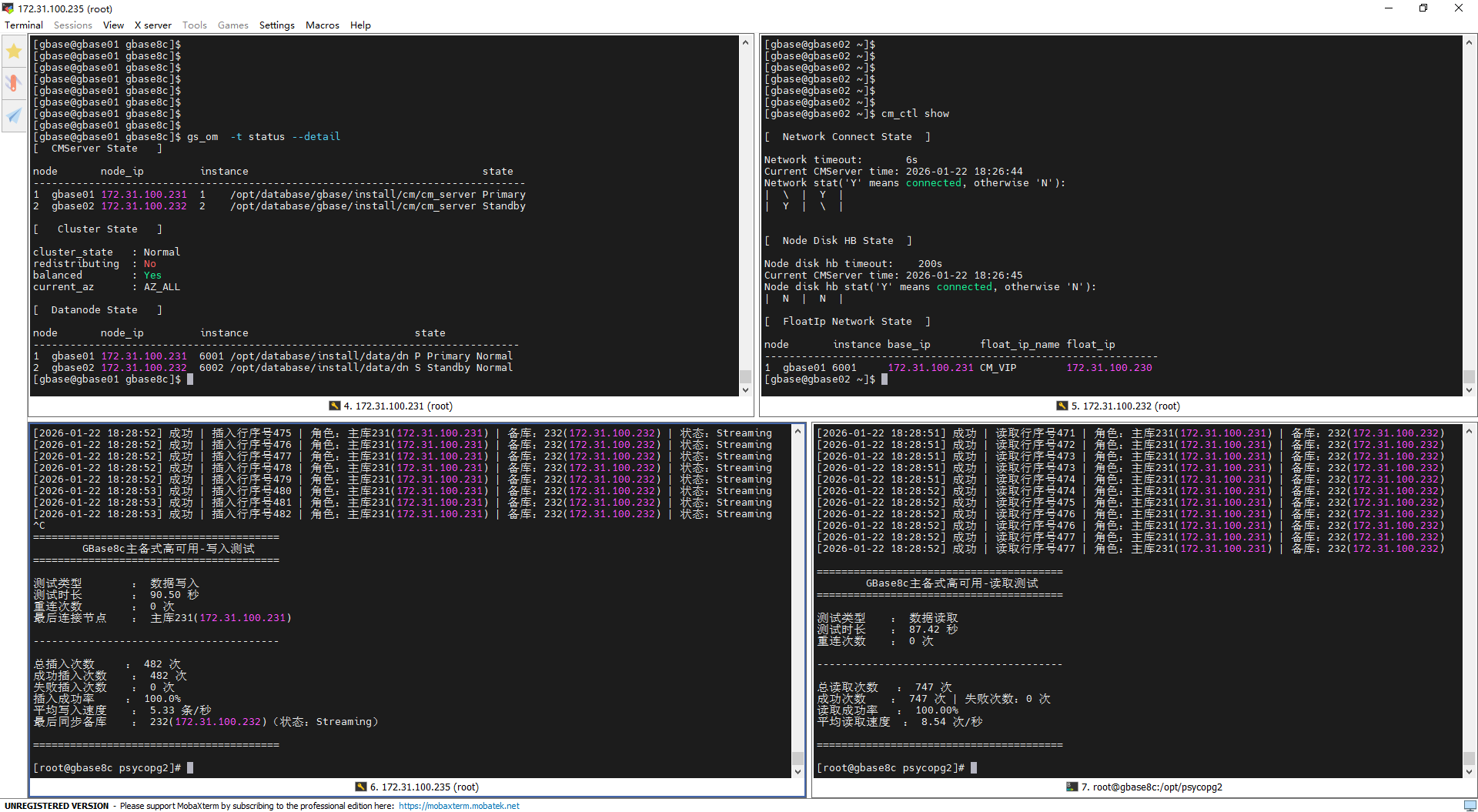
第一次主备倒换(主动倒换)
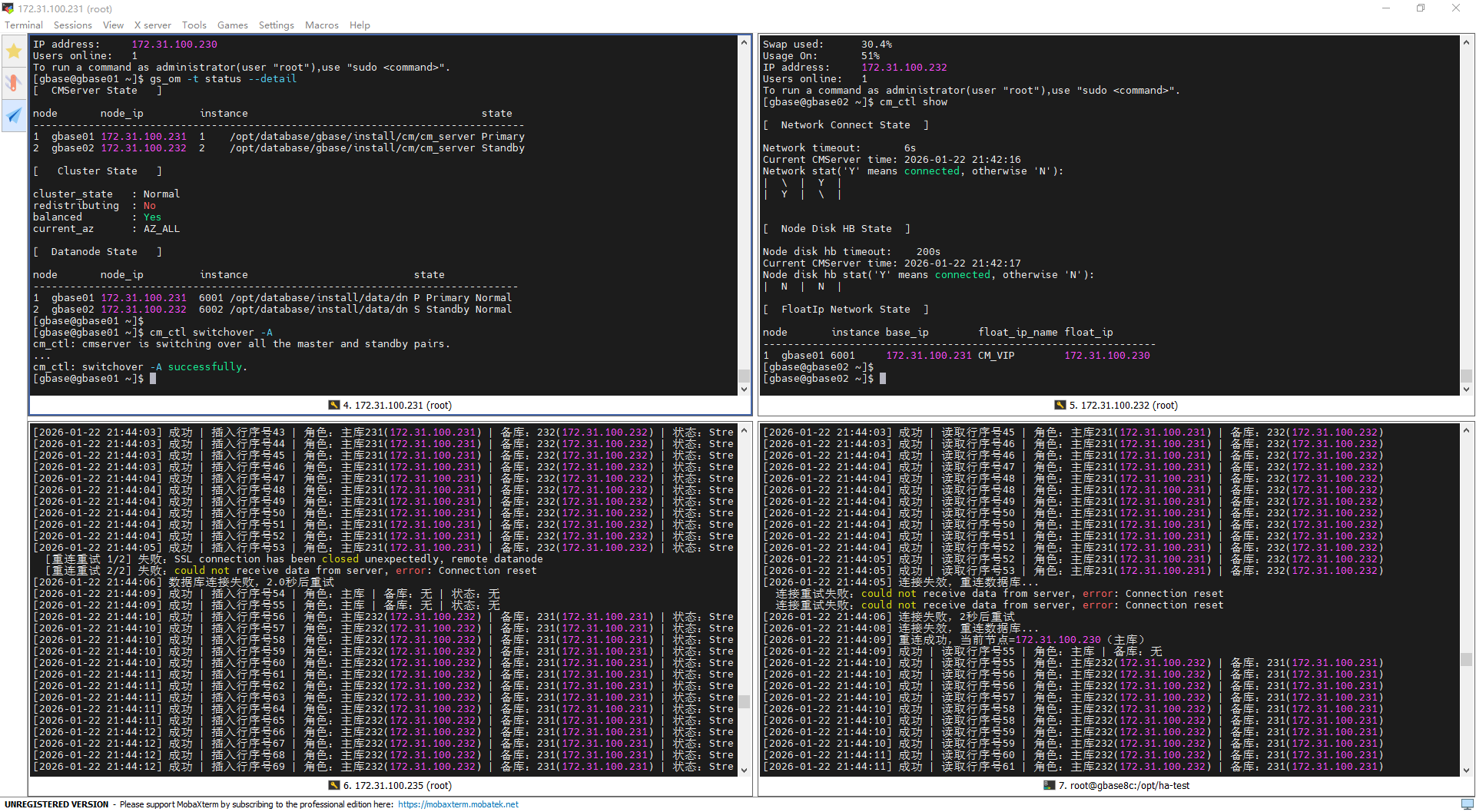
倒换前数据库主节点:
172.31.100.231执行倒换命令:
cm_ctl switchover -A
倒换过程截图:
写入测试输出分析
倒换前(21:44:05):集群状态稳定,231为主库、232为备库,主备同步状态为
Streaming;脚本成功插入行序号53,角色和备库信息识别准确。倒换中(连接中断+重试):主备切换触发原主库231连接断开(SSL连接异常关闭、Connection reset),脚本按配置重试2次均失败,随后按设定等待2秒重试,符合预设重连策略。
倒换后(21:44:09-10):脚本重连成功并接入新主库232,先成功插入行序号54、55(此时备库231尚未建立复制连接,仅识别“主库”角色,备库信息为“无”);后续备库231快速建立同步连接,插入行序号56时已识别出新主库232、备库231,同步状态恢复
Streaming,写入业务无中断、无数据丢失。
读取测试输出分析
倒换前(21:44:05):231为主库、232为备库,脚本成功读取行序号53,角色和备库信息识别正常。
倒换中(连接失效+重试):原主库231连接重置导致读取连接失效,脚本触发重连,前2次重试因连接重置失败,等待2秒后再次触发重连逻辑。
倒换后(21:44:09-10):脚本连接浮动IP 230(已漂移至新主库232)重连成功,先读取到行序号55(此时备库231未完成同步,仅识别“主库”角色,备库信息为“无”);待备库231建立同步连接后,读取时可正常识别新主库232、备库231,数据无丢失、无错乱。
第二次主备倒换(主动倒换)
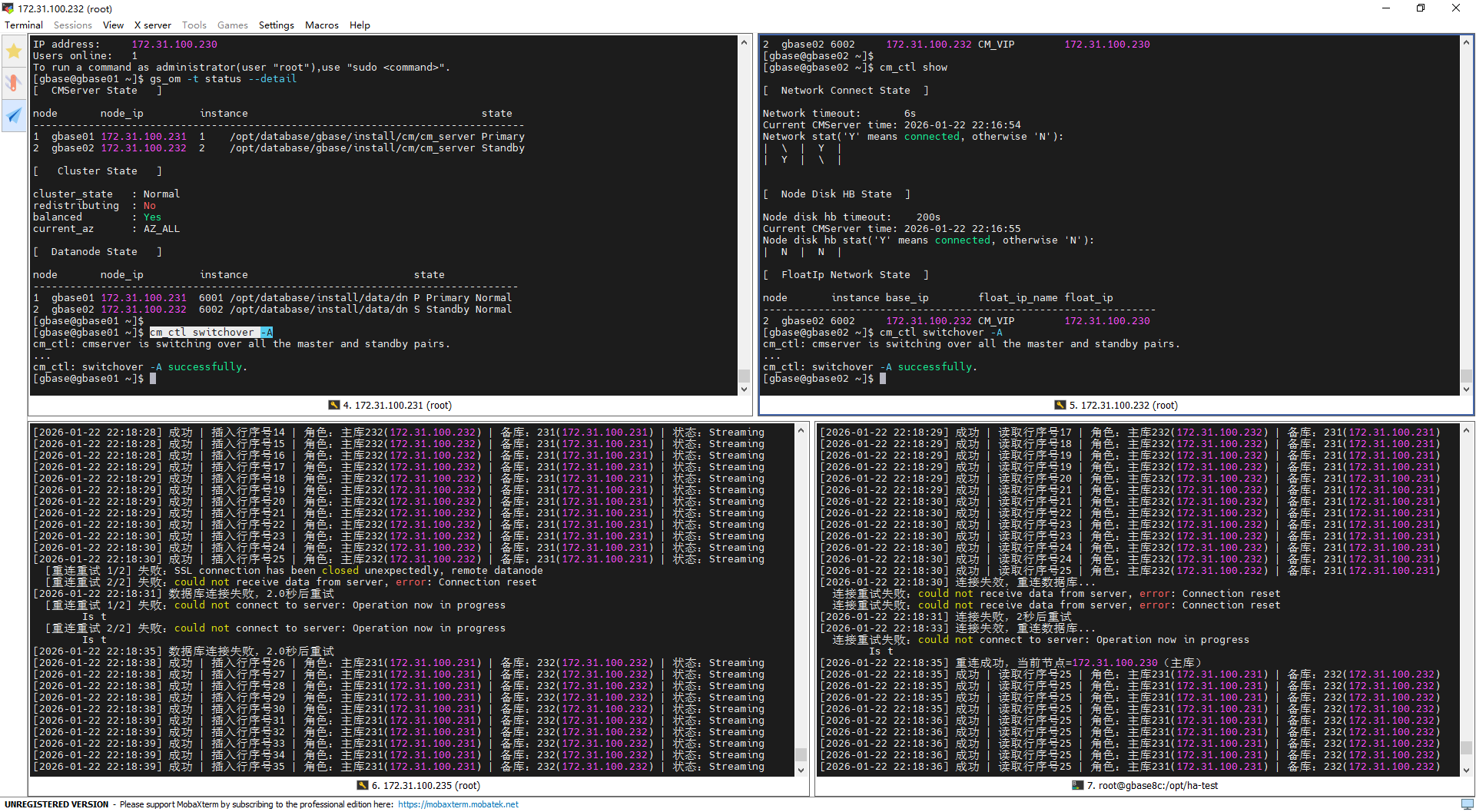
倒换前数据库主节点:
172.31.100.232执行倒换命令:
cm_ctl switchover -A
倒换过程截图:
写入测试输出分析
倒换前(22:18:30):集群状态稳定,232为主库、231为备库,主备同步状态为
Streaming;脚本成功插入行序号25,角色和备库信息识别正常。倒换中(连接中断+重试失败):主备切换触发原主库232连接断开(SSL连接关闭、Connection reset),脚本按配置重试2次均失败;首次重试失败后等待2秒再次尝试,因集群切换中节点未就绪(Operation now in progress)再次重试失败,符合脚本重连策略。
倒换后(22:18:38):脚本重连成功并接入新主库231,成功插入行序号26;此时231为主库、232为备库,同步状态恢复
Streaming,写入业务自动恢复,无数据丢失。
读取测试输出分析
倒换前(22:18:30):232为主库、231为备库,脚本成功读取行序号25,角色和备库信息识别正常。
倒换中(连接失效+重试):原主库232连接重置导致读取连接失效,脚本触发重连,前2次重试因连接重置失败,等待2秒后再次重连,又因节点未就绪(Operation now in progress)重试失败。
倒换后(22:18:35):脚本连接浮动IP 230(已漂移至新主库231)重连成功,立即读取到行序号25(数据无丢失),且可正常识别新主库231、备库232的角色信息,读取业务快速恢复。
第三次主备倒换(主节点重启)
倒换前数据库主节点:
172.31.100.231执行主节点重启命令:
sudo reboot now
重启过程截图:
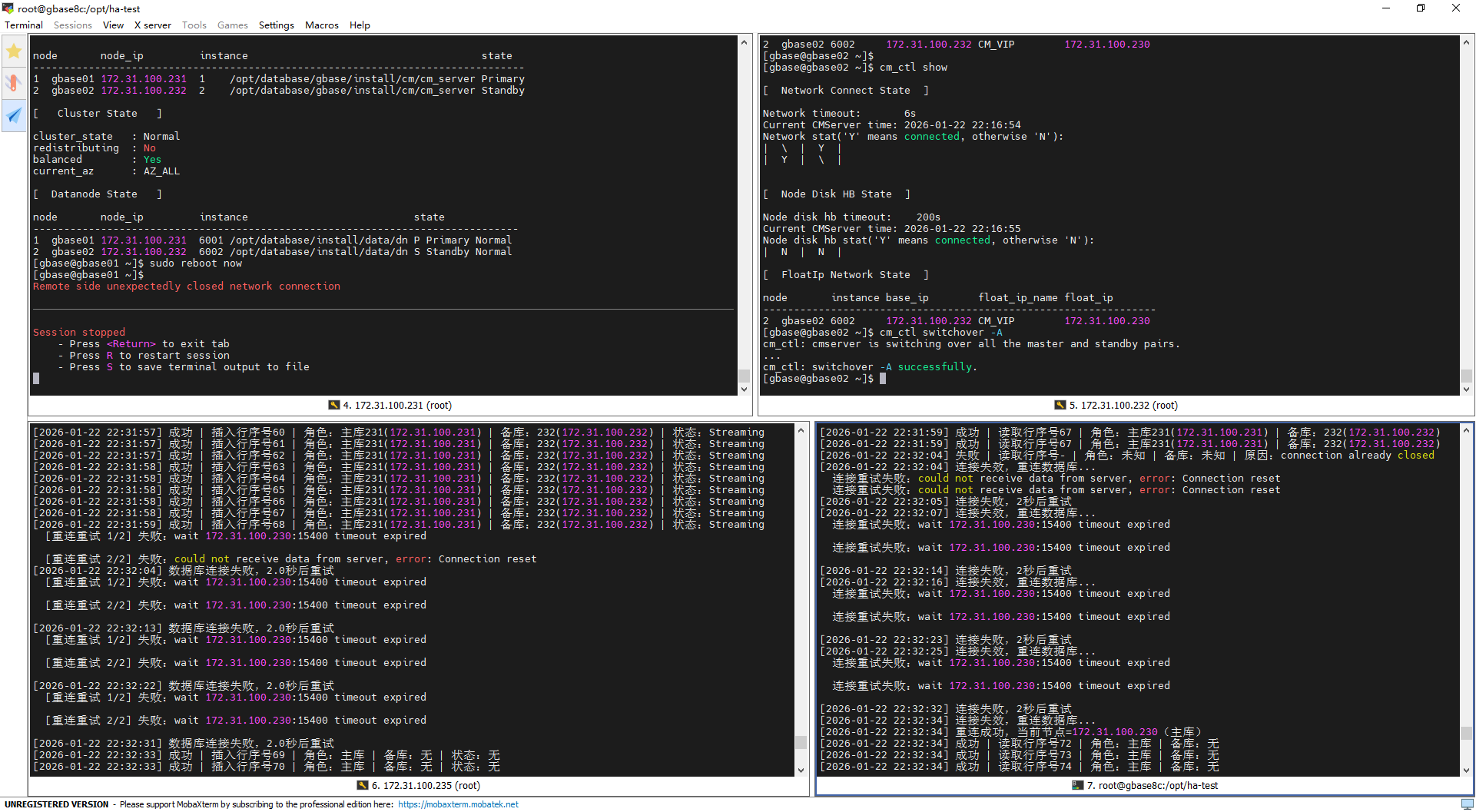
写入测试输出分析
重启前(22:31:59):集群状态稳定,231为主库、232为备库,主备同步状态为
Streaming;脚本成功插入行序号68,角色和备库信息识别准确。重启中(连接超时+多次重试):主节点231操作系统重启触发浮动IP 230:15400连接超时,脚本先因连接重置重试2次失败;后续多轮重试均因浮动IP连接超时失败,每轮失败后按设定等待2秒重试(该超时为节点重启过程中数据库服务未就绪的正常现象),符合脚本重连策略。
重启后(22:32:33):脚本最终重连成功并接入新主库(原备库232),成功插入行序号69;此时新主库刚接管,备库(原主库231)尚未完成重启和同步连接建立,仅识别“主库”角色,备库及同步状态均为“无”,写入业务恢复且无数据丢失。
读取测试输出分析
重启前(22:31:59):231为主库、232为备库,脚本成功读取行序号67,角色和备库信息识别正常。
重启中(连接失效+多轮超时重试):主节点重启导致连接关闭(connection already closed),脚本触发重连,先因连接重置重试2次失败;后续多轮重连均因浮动IP 230:15400连接超时失败,每轮失败后等待2秒重试,期间读取失败且无法识别角色/备库信息。
重启后(22:32:34):脚本连接浮动IP 230(已漂移至新主库232)重连成功,成功读取到行序号72(数据无丢失、无错乱);此时新主库刚接管,备库未建立同步连接,仅识别“主库”角色,备库信息为“无”,读取业务快速恢复。
第四次主备倒换(备节点重启)
倒换前数据库主节点:
172.31.100.232前置条件:原主节点重启完成且集群状态恢复至
normal,当前该节点为备节点,无抢占主库行为;执行备节点重启命令:
reboot now
重启过程截图:
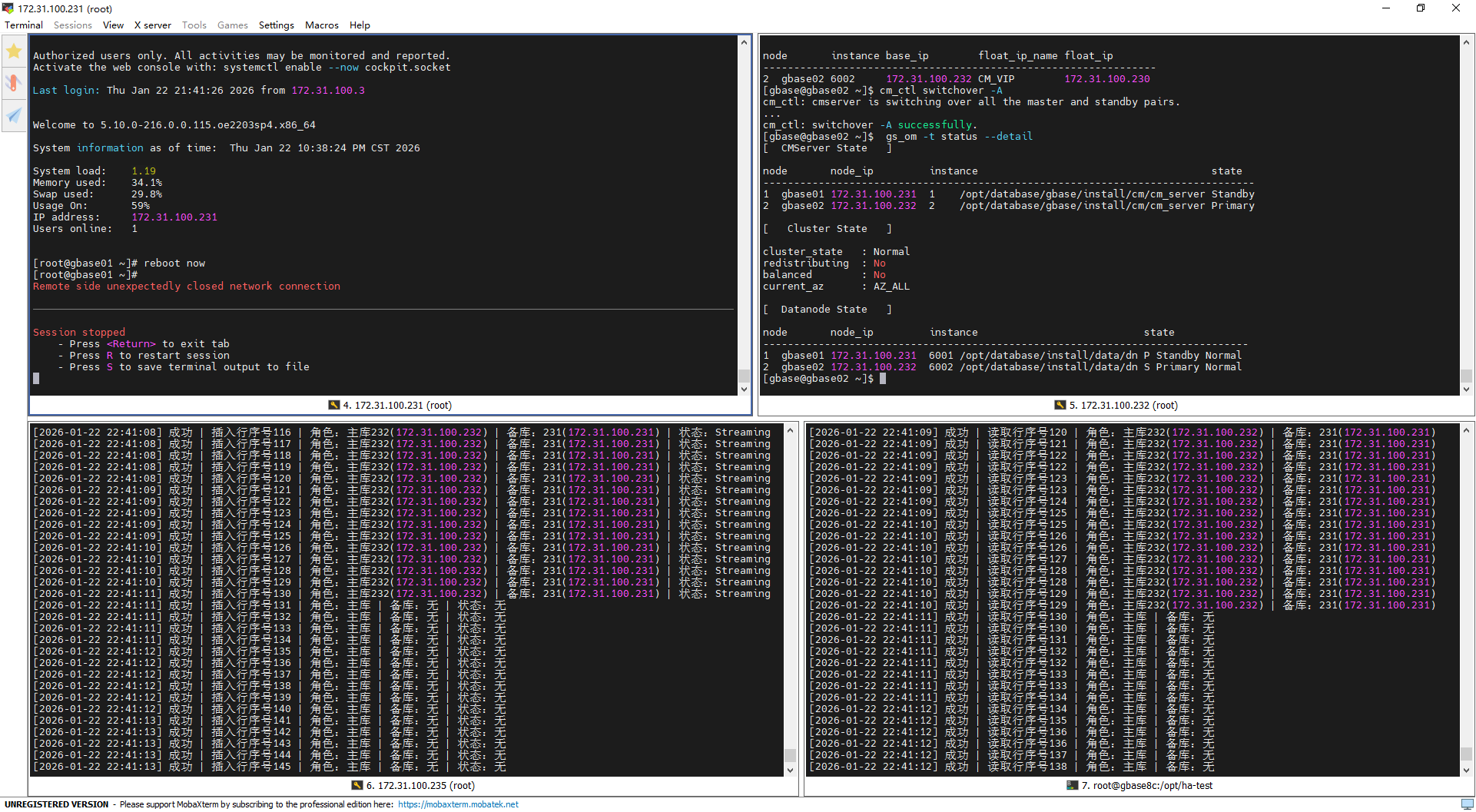
写入测试输出分析
重启前(22:41:10-11):集群状态稳定,232为主库、231为备库,主备同步状态为
Streaming;脚本连续成功插入行序号129、130,角色和备库信息识别准确,写入业务无异常。重启中(备库连接断开):备节点231操作系统重启触发其与主库232的复制连接断开,脚本插入行序号131、132时,因
pg_stat_replication无备库连接记录,仅识别“主库”角色,备库及同步状态均为“无”;但写入操作未中断,仍成功完成插入。
读取测试输出分析
重启前(22:41:10):232为主库、231为备库,脚本连续成功读取行序号129,角色和备库信息识别正常,读取业务稳定。
重启中(备库信息未识别):备节点231重启导致复制连接断开,脚本读取行序号130时,无法识别备库信息,仅识别“主库”角色,备库信息为“无”;但读取操作未失败,仍成功读取到最新行序号。
测试总结
本次测试覆盖主动主备倒换、主节点重启、备节点重启三类核心场景,共完成四次主备倒换验证,整体表现完全符合预期,充分验证了GBase8c主备集群的高可用能力:
主库故障(主动倒换、重启)时,集群可自动完成服务切换,浮动IP正常漂移,脚本通过重连机制自动接入新主库,写入/读取业务无永久性中断,最终均恢复正常,无数据丢失、无错乱;
备库故障(重启)时,不影响主库核心写入/读取业务,仅临时无法识别备库同步信息,业务全程无失败、无重试,体现备库作为“备份角色”的设计定位;
测试过程中出现的“Connection reset”“浮动IP超时”“备库无识别”等现象,均为集群故障切换的正常表现,脚本重试机制可有效适配故障窗口,集群高可用设计目标达成。